








新闻中心 
深度学习中的各类上采样算子
 2025-08-01
2025-08-01 浏览次数:次
浏览次数:次 返回列表
返回列表本文介绍了深度学习分割任务中Decoder阶段的多种上采样方法。包括规则上采样的Upsample(如双线性插值)、通过周期筛选实现的PixelShuffle、基于最大值位置还原的MaxUnPool2D、需学习参数的Conv2DTranspose(反卷积),以及不规则上采样的grid_sample,并结合示例展示了各方法的效果与特点。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

深度学习中的各类上采样算子
在做分割的时候,我们经常会遇到Decoder时对特征进行上采样,比较常见的就是下面这个:
x = F.interpolate(x, scale_factor=2., mode="bilinear")
但除了这个上采样的方法外,还有许多的方法都可以将当前Tensor的大小由[H, W]变为[H*r, W*r]。说不定把这些上采样方法换来换去能找到一个对当前的任务有着更好的效果的上采样方法。
下面我们对一些(了解有限,只知道这么多)常用的上采样方法进行一些介绍。
准备
这里主要是导入一些库以及写几个ndarray和tensor转换的函数,方便显示。
示例图像方面准备了一张李化元(希望下集别刀了)大头照,其他的通道数很多的特征也差不多。
In [21]import cv2import numpy as npimport paddleimport paddle.nn as nnimport paddle.nn.functional as Fimport matplotlib.pyplot as plt
%matplotlib inlinedef to_tensor(image):
# H, W, C -> 1, C, H, W
# uint8 -> float32
# ndarray -> tensor
return paddle.to_tensor(image.transpose((2, 0, 1))[None], dtype="float32")def to_ndarray(tensor):
# 1, C, H, W -> H, W, C
# float32 -> uint8
# tensor -> ndarray
return tensor.squeeze().numpy().transpose((1, 2, 0)).astype("uint8")def show(im1, im2, im3=None):
plt.figure(figsize=(15, 5))
plt.subplot(131);plt.imshow(im1);plt.title("raw image") # 原图
plt.subplot(132);plt.imshow(im2);plt.title("down image") # 下采样后的图
if im3 is not None:
plt.subplot(133);plt.imshow(im3);plt.title("up image") # 上采样后的结果
plt.show()
In [22]
img_path = "lhy.jpg"img = cv2.cvtColor(cv2.imread(img_path), cv2.COLOR_BGR2RGB) # 图像准备
1. Upsample
该OP用于调整一个batch中图片的大小。
输入为3-D Tensor时形状为(num_batches, channels, in_w),输入为4-D Tensor时形状为(num_batches, channels, in_h, in_w)或者(num_batches, in_h, in_w, channels),输入为5-D Tensor时形状为(num_batches, channels, in_d, in_h, in_w)或者(num_batches, in_d, in_h, in_w, channels),并且调整大小只适用于深度,高度和宽度对应的维度。
这个算子和前面说到的F.interpolate差不多,是一个规则上采样的方法,有最近邻法、双线性插值、双三次插值等。
以双线性插值为例,如下图所示,根据离待插值最近的个已知值来计算待插值,每个已知值的权重由距离待插值距离决定,距离越近权重越大。其中P就可以由R1和R2插值而来,而R1和R2分别由Q11/Q21和Q12/Q22插值得到。
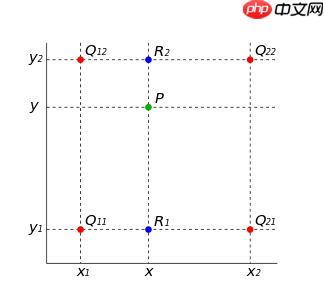
图源:https://www.cnblogs.com/yssongest/p/5303151.html
下图看起来的效果不错,将一些锯齿都变得比较平滑了。
In [23]upnet = nn.Upsample(scale_factor=2., mode="BILINEAR") # 放大2倍,以双线性插值的方式进行half_img = cv2.resize(img, None, None, 0.5, 0.5, cv2.INTER_LINEAR) upsample_pred = upnet(to_tensor(half_img)) show(img, half_img, to_ndarray(upsample_pred))
<Figure size 1080x360 with 3 Axes>
2. PixelShuffle
该算子将一个形为[N, C, H, W]或是[N, H, W, C]的Tensor重新排列成形为 [N, C/r**2, H*r, W*r]或 [N, H*r, W*r, C/r**2] 的Tensor。这样做有利于实现步长(stride)为1/r的高效sub-pixel(亚像
素)卷积。详见Shi等人在2016年发表的论文 Real Time Single Image and Video Super Resolution Using an Efficient Sub Pixel Convolutional Neural Network 。
 素)卷积。详见Shi等人在2016年发表的论文 Real Time Single Image and Video Super Resolution Using an Efficient Sub Pixel Convolutional Neural Network 。
素)卷积。详见Shi等人在2016年发表的论文 Real Time Single Image and Video Super Resolution Using an Efficient Sub Pixel Convolutional Neural Network 。PixelShuffle常用在超分之中,经过PixelShuffle上采样会减少通道层的数目。通过卷积先得到 r^2 个通道的特征图(特征图大小和输入低分辨率图像一致),然后通过周期筛选(periodic shuffing)的方法得到这个高分辨率的图像,其中rrr为上采样因子(upscaling factor),也就是图像的扩大倍率。根据下图中后面两个图,比较容易理解PixelShuffle是怎么做的。使用中也常常按照这个流程,先训练得到更多的特征图,再使用PixelShuffle上采样,这样就能保证通道数不变,并放大了图像长宽。

图源:https://www.jianshu.com/p/71d6a9374899
 Motiff妙多
Motiff妙多
Motiff妙多是一款AI驱动的界面设计工具,定位为“AI时代设计工具”
 334
查看详情
334
查看详情

这里由于原图是3通道,长宽各扩大2倍则需要通道数为原来的1/4,因此在这里演示的时候为了显示,在使用PixelShuffle的时候将图像复制了4份叠在一起,组成了12通道的图像,然后在PixelShuffle后变为3通道。
In [28]upnet = nn.PixelShuffle(upscale_factor=2) # 放大2倍,通道数变为1/4half_img = cv2.resize(img, None, None, 0.5, 0.5, cv2.INTER_LINEAR) half_img = np.concatenate([half_img] * 4, axis=-1) # C: 3 -> 12pixelshuffle_pred = upnet(to_tensor(half_img)) show(img, half_img[:, :, :3], to_ndarray(pixelshuffle_pred))
<Figure size 1080x360 with 3 Axes>
3. MaxUnPool2D
该接口用于构建 MaxUnPool2D 类的一个可调用对象,根据输入的input和最大值位置计算出池化的逆结果。所有非最大值设置为零。
MaxPool和AvgPool分别是对图像进行最大池化和平均池化,而对应的反池化就可以将结果还原到原来的大小。由于AvgPool是一个取平均的操作,反池化直接复制出多份平均值即可,因此没有专门的AvgUnPool函数,直接用Upsample即可。而MaxUnPool需要将最大值还原到对应的位置,因此MaxPool可以设置保存最大值索引的位置,MaxUnPool则需要根据这个位置将最大值还原到原来的位置,并在其他位置补充零。如下图所示:
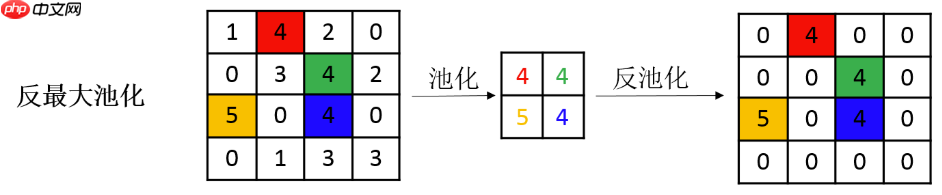
图源:https://blog.csdn.net/quiet_girl/article/details/84579038
下图中看起来有一些不同的、单独的颜色块,是因为三个通道中的最大值索引是有区别的,因此还原回去也不都是同一个位置。
In [52]upnet = nn.MaxUnPool2D(2, 2) half_img, indices = F.max_pool2d(to_tensor(img), 2, 2, return_mask=True) # 需要返回索引maxunpool_pred = upnet(half_img, indices) # 根据索引找到原始位置show(img, to_ndarray(half_img), to_ndarray(maxunpool_pred))
<Figure size 1080x360 with 3 Axes>
4. Conv2DTranspose
二维转置卷积层(Convlution2d transpose layer)
该层根据输入(input)、卷积核(kernel)和空洞大小(dilations)、步长(stride)、填充(padding)来计算输出特征层大小或者通过output_size指定输出特征层大小。输入(Input)和输出(Output)为NCHW或NHWC格式,其中N为批尺寸,C为通道数(channel),H为特征层高度,W为特征层宽度。卷积核是MCHW格式,M是输出图像通道数,C是输入图像通道数,H是卷积核高度,W是卷积核宽度。如果组数大于1,C等于输入图像通道数除以组数的结果。转置卷积的计算过程相当于卷积的反向计算。转置卷积又被称为反卷积(但其实并不是真正的反卷积)。欲了解转置卷积层细节,请参考下面的说明和参考文献。如果参数bias_attr不为False, 转置卷积计算会添加偏置项。
不同于上面的上采样操作(如果PixelShuffle没算上前面的卷积步骤),反卷积是一种需要学习的上采样方法,其示意图如下所示。因此反卷积会带来额外的参数,但如果学习的不错,可能会对后续的任务的效果好于不用学习的方法。当然这就见仁见智了。
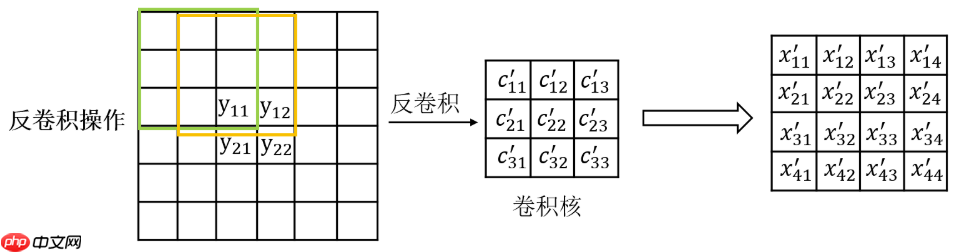
图源:https://blog.csdn.net/quiet_girl/article/details/84579038
下面为了演示简单训练了100次反卷积的卷积核,当然,直接两个RGB图像的mse_loss和这样搞起来实在是有点坑,效果也不多说,只是表明ConvTranspose是可以训练的。这里的简单训练至少让它看起来像个人了。不过大家也都提到了(也可以看到)反卷积后棋盘格效应 (checkerboard pattern) 出现。
In [49]upnet = nn.Conv2DTranspose(3, 3, 4, 2, 1)
half_img = cv2.resize(img, None, None, 0.5, 0.5, cv2.INTER_LINEAR)
upnet.train() # 训练模式opt = paddle.optimizer.AdamW(0.001, parameters=upnet.parameters())for _ in range(100): # 跑100次
upsample_pred = upnet(to_tensor(half_img))
loss = F.mse_loss(upsample_pred, to_tensor(img))
loss.backward()
opt.step()
upnet.eval() # 评估模式convtranspose_pred = upnet(to_tensor(half_img))
show(img, half_img, to_ndarray(convtranspose_pred))
<Figure size 1080x360 with 3 Axes>
5. grid_sample
该OP基于flow field网格的对输入X进行双线性插值采样。网格通常由affine_grid生成, shape为[N, H, W, 2],是shape为[N, H, W]的采样点张量的(x, y)坐标。 其中,x坐标是对输入数据X的第四个维度(宽度维度)的索引,y坐标是第三维度(高维度)的索引,最终输出采样值为采样点的4个最接近的角点的双线性插值结果,输出张量的shape为[N, C, H, W]。
不同于Upsample的规则上采样,grid_sample是一种不规则的上采样,它会依照一个flow-field网格(比如光流,体素流等),根据这个网格中每个位置提供的坐标信息(这里指input中pixel的坐标),将input中对应位置的像素值填充到grid指定的位置,得到最终的输出。在一些有guide结构的网络中,会通过计算边缘流、光流等等,然后使用grid_sample将其他特征按照该网格进行非规则的上采样。grid_sample的示意如下图所示:
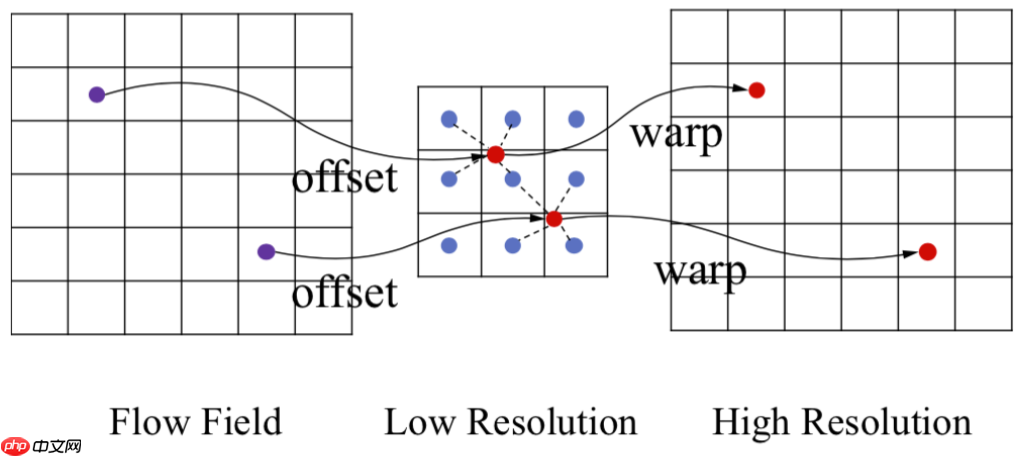
图源:https://blog.csdn.net/qq_34914551/article/details/107559031
下面的结果由于直接使用一个上下左右均为-1到1的grid会使得上采样的结果与规则上采样的结果相同,因此为其增加了一点位置的扰动,使得上采样后的结果不相同。
In [65]upnet = F.grid_sample# 创建一个水平和竖直方向都是-1到1的格网h, w = img.shape[:2] h_grid = paddle.linspace(-1.0, 1.0, h).reshape([-1, 1]).tile([w]) w_grid = paddle.linspace(-1.0, 1.0, w).reshape([-1, 1]).tile([h]).transpose((1, 0)) grid = paddle.concat([w_grid.unsqueeze(2), h_grid.unsqueeze(2)], axis=2)[None]# 故意对其进行随机扰动,注释这一行恢复的原图将同1grid += (paddle.randn((1, h, w, 2), dtype="float32") / 200) half_img = cv2.resize(img, None, None, 0.5, 0.5, cv2.INTER_LINEAR) gridsample_pred = upnet(to_tensor(half_img), grid) # 以grid来引导图像上采样show(img, half_img, to_ndarray(gridsample_pred))
<Figure size 1080x360 with 3 Axes>
以上就是深度学习中的各类上采样算子的详细内容,更多请关注其它相关文章!
# 都是
# 小网站推广方法
# 营销属性视频怎么推广的
# 可克达拉营销推广半托管
# 昆山网站建设优化企业
# 灰帽seo优化引流
# 网站像素优化什么意思呀
# 怎么拉高关键词搜索排名
# 洛阳保洁网站建设多少钱
# seo内容助手
# 德阳高端网站推广费用
# 如下图
# 是一种
# 也不
# 是一个
# qq
# 一言
# 所示
# 中文网
# 插值
# 腾讯
# type
# upscale
# fig
# igs
# red
# 排列
# 区别
# ai
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
汽车上power是什么意思
丰田type-c接口是什么
满射为什么没有逆映射
如何在命令行执行存储过程
镜像ao3链接入口
春运大巴上抢票怎么抢票
命令行如何打开打印机
远程桌面如何发送命令
春运哪天抢票最好预约
固态硬盘2m如何修复
如何安装大华固态硬盘
推特是什么软件国内可以使用吗
网络光刻机是干什么用的
vivo手机nfc功能是什么意思
华为5g手机怎么用4g网络
问一下市盈率是什么意思
春运抢票要用抢票软件吗
play的三人称单数和过去式
eraser是什么意思
夸克是什么空间单位
win10windows资源管理器在哪里打开
win10如何开启命令行
在遥控器中power是什么意思
ready是什么意思
iphone拍电子屏有横条如何解决
1kb等于多少字节
如何看固态硬盘信息
哪些编程软件需用typescript
输入命令如何换行
如何安装tree命令
单片机log怎么看
如何通过命令行启动tomcat
vi命令如何退出编辑模式
电焊机power灯亮是什么意思
春运哪天抢票最好
新买的固态硬盘如何查
学typescript有什么用
如果公司ttm市盈率为负数是什么意思
5G类似微信的聊天软件有哪些
所有删除的聊天记录都可以恢复吗?
市盈率ttm是什么意思
市盈率是负数是什么意思
1s等于多少ms
爱奇艺会员qq登录可以几个人用?
夸克是什么用途
怎么在爱奇艺中投屏到电视最新方法
360n6锁屏壁纸怎么设置
点焊机接触器上power是什么意思
单片机怎么判定高电平
typescript在浏览器里怎么用
