








新闻中心 
ERFNet:用于实时语义分割的高效残差分解卷积神经网络
 2025-07-17
2025-07-17 浏览次数:次
浏览次数:次 返回列表
返回列表语义分割是一项具有挑战性的任务,它以统一的方式解决智能车辆的大部分感知需求。深度神经网络擅长这项任务,因为它们可以进行端到端训练,以在像素级别准确分类图像中的多个对象类别。然而,在最先进的语义分割方法中还没有在高质量和计算资源之间进行良好的权衡,这限制了它们在实际车辆中的应用。而ERFNet是一种深度架构,该架构能够实时运行的同时提供准确的语义分割。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

用于实时语义分割的高效残差分解卷积神经网络
语义分割是一项具有挑战性的任务,它以统一的方式解决智能车辆的大部分感知需求。深度神经网络擅长这项任务,因为它们可以进行端到端训练,以在像素级别准确分类图像中的多个对象类别。然而,在最先进的语义分割方法中还没有在高质量和计算资源之间进行良好的权衡,这限制了它们在实际车辆中的应用。而ERFNet是一种深度架构,该架构能够实时运行的同时提供准确的语义分割。参考资料:
- Efficient ConvNet for Real-time Semantic Segmentation
- 2025中国华录杯数据湖算法大赛(车道检测赛道)冠军方案
一、数据集简介
本项目使用的是第17届全国大学生智能汽车竞赛完全模型组线上资格赛的数据集。本次大赛提供3类共计16000张图像数据。
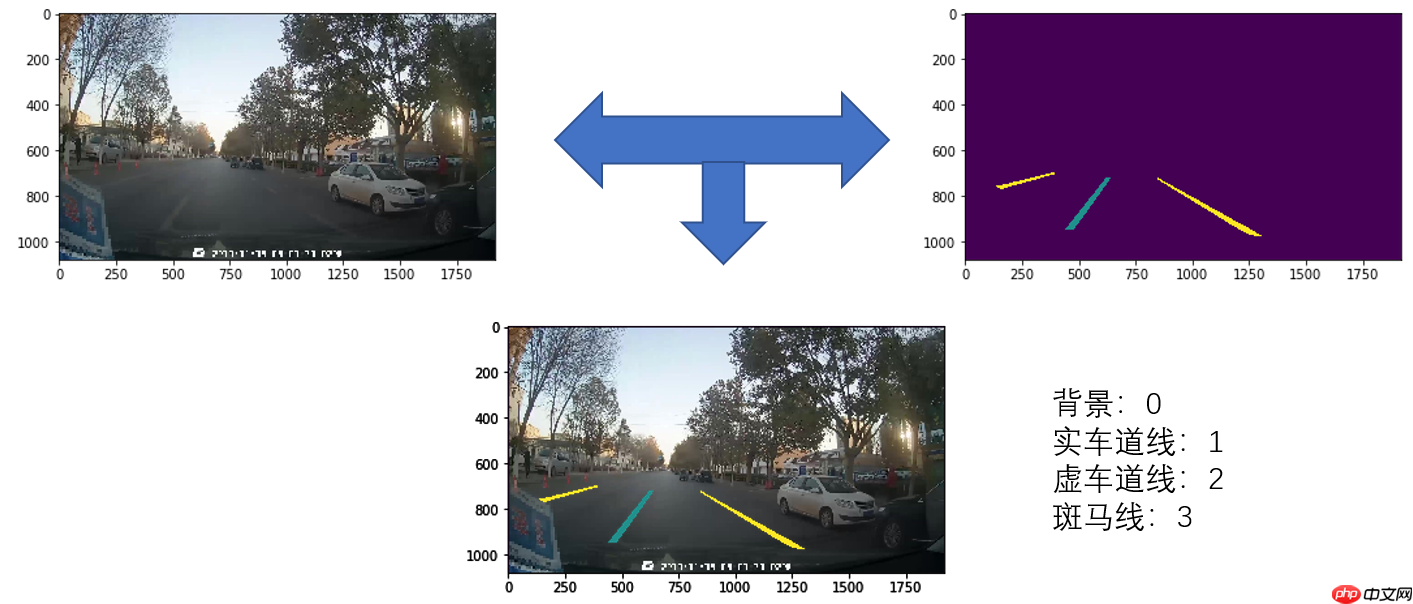
该数据集采用单通道标注图片,每一种像素值代表一种类别,像素标注类别从0开始递增,即0,1,2,3这4种类别,分别为背景、实车道线、虚车道线、斑马线。
In [2]# 解压数据集!unzip -q data/data125507/car_data_2025.zip -d data/data125507/
二、模型组网
ERFNet旨在解决通常采用的残差层版本中固有的效率限制,该残差层用于最近几个在分类和分割任务中达到最高精度的ConvNet。与现有体系结构相比,该体系结构更有效地 利用了参数,使网络在保持最高效率的同时获得了非常高的分割精度。
利用了参数,使网络在保持最高效率的同时获得了非常高的分割精度。
ERFNet的网络架构是编码-解码器架构。与像FCN架构相反,在这种架构中,不同层的特征映射需要被融合,以获得一个细腻的输出。
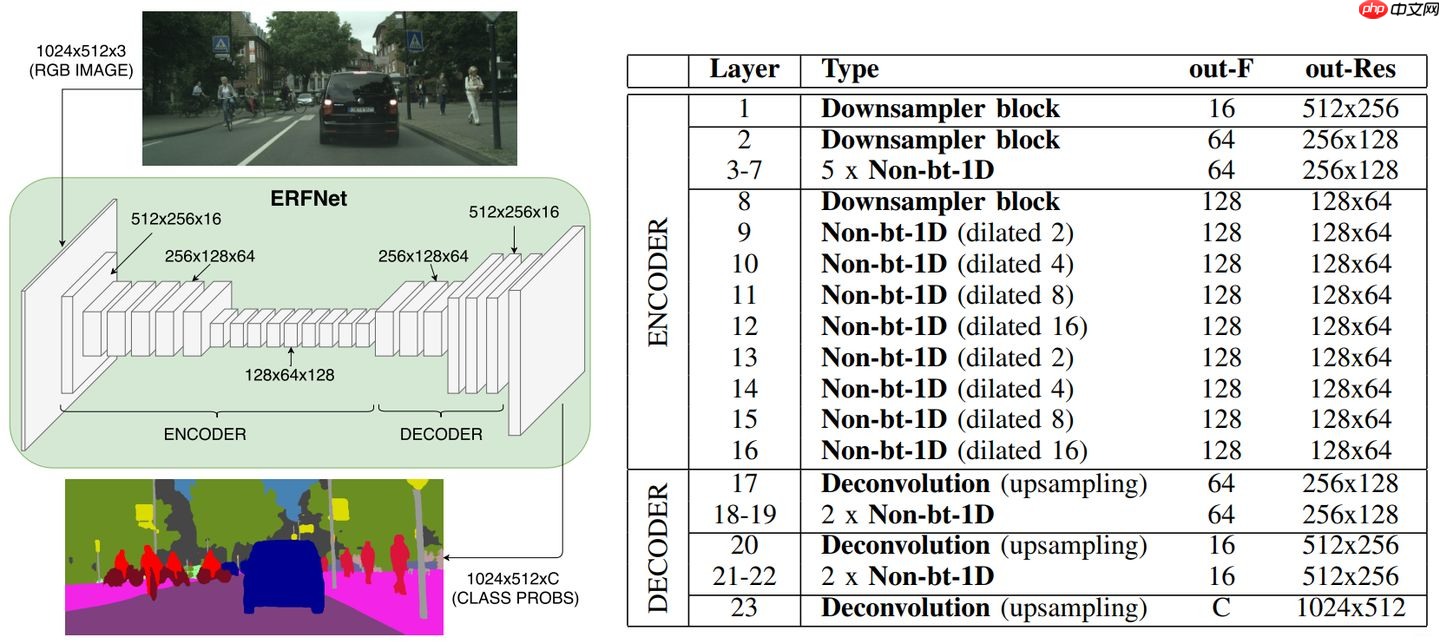
1.残差分解块
ResNet提出了两种残差模块,其结构如下图里的a、b所示。两者有着相似的参数和接近的精度。但是,bottleneck需要更少的计算资源,随着深度增加这个特点更加划算,因此更加通用。但是,non-bottleneck模块能够获得更好的精度,并且bottleneck仍存在退化问题。
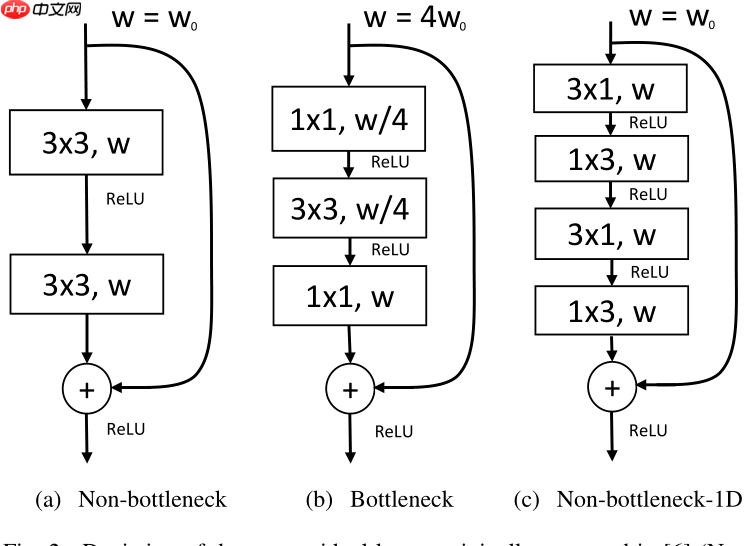
于是ERFNet的作者提出了一个新的版本,如上图c所示。其代码如下所示:
 美图云修
美图云修
商业级AI影像处理工具
 50
查看详情
50
查看详情
 In [2]
In [2]
import paddleclass non_bottleneck_1d(paddle.nn.Layer):
def __init__(self, chann, dropprob, dilated):
super().__init__()
self.conv3x1_1 = paddle.nn.Conv2D(in_channels=chann, out_channels=chann, kernel_size=(3, 1), stride=1, padding=(1, 0), bias_attr=True)
self.conv1x3_1 = paddle.nn.Conv2D(in_channels=chann, out_channels=chann, kernel_size=(1, 3), stride=1, padding=(0, 1), bias_attr=True)
self.bn1 = paddle.nn.BatchNorm(chann, epsilon=1e-03)
self.conv3x1_2 = paddle.nn.Conv2D(in_channels=chann, out_channels=chann, kernel_size=(3, 1), stride=1, padding=(1 * dilated, 0), bias_attr=True,
dilation=(dilated, 1))
self.conv1x3_2 = paddle.nn.Conv2D(in_channels=chann, out_channels=chann, kernel_size=(1, 3), stride=1, padding=(0, 1 * dilated), bias_attr=True,
dilation=(1, dilated))
self.bn2 = paddle.nn.BatchNorm(chann, epsilon=1e-03)
self.dropout = paddle.nn.Dropout(dropprob)
self.p = dropprob def forward(self, input):
output = self.conv3x1_1(input)
output = paddle.nn.functional.relu(output)
output = self.conv1x3_1(output)
output = self.bn1(output)
output = paddle.nn.functional.relu(output)
output = self.conv3x1_2(output)
output = paddle.nn.functional.relu(output)
output = self.conv1x3_2(output)
output = self.bn2(output) if self.p != 0:
output = self.dropout(output) return paddle.nn.functional.relu(output + input)
2.编码器
下采样虽然获得了粗糙的输出,但降低了计算量,网络进行了三次下采样,并借鉴了ENet的早期下采样模式:即将2x2的最大池化和3x3卷积(步长为2)concat在一起。并且在提出的resnet block上交错使用空洞卷积,以获得更多的信息。
其代码如下所示:
In [3]class DownsamplerBlock(paddle.nn.Layer):
def __init__(self, ninput, noutput):
super().__init__()
self.conv = paddle.nn.Conv2D(in_channels=ninput, out_channels=noutput-ninput, kernel_size=3,
stride=2, padding=1, bias_attr=True)
self.pool = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.bn = paddle.nn.BatchNorm(noutput, epsilon=1e-3) def forward(self, input):
output = paddle.concat(x=[self.conv(input), self.pool(input)], axis=1)
output = self.bn(output) return paddle.nn.functional.relu(output)class Encoder(paddle.nn.Layer):
def __init__(self, num_classes):
super().__init__()
self.initial_block = DownsamplerBlock(3, 16)
self.layers = paddle.nn.LayerList()
self.layers.append(DownsamplerBlock(16, 64)) for x in range(0, 5): # 5 times
self.layers.append(non_bottleneck_1d(64, 0.1, 1))
self.layers.append(DownsamplerBlock(64, 128)) for x in range(0, 2): # 2 times
self.layers.append(non_bottleneck_1d(128, 0.1, 2))
self.layers.append(non_bottleneck_1d(128, 0.1, 4))
self.layers.append(non_bottleneck_1d(128, 0.1, 8))
self.layers.append(non_bottleneck_1d(128, 0.1, 16)) # only for encoder mode:
self.output_conv = paddle.nn.Conv2D(in_channels=128, out_channels=num_classes, kernel_size=1, stride=1, padding=0, bias_attr=True) def forward(self, input, predict=False):
output = self.initial_block(input) for layer in self.layers:
output = layer(output) if predict:
output = self.output_conv(output) return output
3.解码器
上采样部分仅有调节细腻度并与输入匹配的作用,采用了和ENet类似的架构。不同的是,没有采用ENet的最大反池化,而是采用了简单的步长为2的反卷积。
In [ ]class UpsamplerBlock(paddle.nn.Layer):
def __init__(self, ninput, noutput, output_size=[16, 16]):
super().__init__()
self.conv = paddle.nn.Conv2DTranspose(ninput, noutput, kernel_size=3, stride=2, padding=1, bias_attr=True)
self.bn = paddle.nn.BatchNorm(noutput, epsilon=1e-3)
self.output_size = output_size def forward(self, input):
output = self.conv(input, output_size=self.output_size)
output = self.bn(output) return paddle.nn.functional.relu(output)class Decoder(paddle.nn.Layer):
def __init__(self, num_classes, raw_size=[576, 1640]):
super().__init__()
self.layers = paddle.nn.LayerList()
self.raw_size = raw_size
self.layers.append(UpsamplerBlock(128, 64, output_size=[raw_size[0] // 4, raw_size[1] // 4]))
self.layers.append(non_bottleneck_1d(64, 0, 1))
self.layers.append(non_bottleneck_1d(64, 0, 1))
self.layers.append(UpsamplerBlock(64, 16, output_size=[raw_size[0] // 2, raw_size[1] // 2]))
self.layers.append(non_bottleneck_1d(16, 0, 1))
self.layers.append(non_bottleneck_1d(16, 0, 1))
self.output_conv = paddle.nn.Conv2DTranspose(16, num_classes, kernel_size=2, stride=2, padding=0, bias_attr=True) def forward(self, input):
output = input
for layer in self.layers:
output = layer(output)
output = self.output_conv(output, output_size=[self.raw_size[0], self.raw_size[1]]) return output
4.完整ERFNet
完整的ERFNet的代码如下所示:
In [ ]class ERFNet(paddle.nn.Layer):
def __init__(self, num_classes, raw_size=[576, 1640]):
super().__init__()
self.encoder = Encoder(num_classes)
self.decoder = Decoder(num_classes, raw_size=raw_size) def forward(self, input):
output = self.encoder(input) return self.decoder.forward(output)
三、模型训练
为了方便各位开发者运行,这里加载了在Cityscape数据集上预训练的权重,大家可以基于该权重做预训练。
In [3]!python Lane-Detection-with-ERFNet/train_erfnet_paddle.py --epochs 1 -b 8 --lr 0.01
W0305 21:12:08.735818 621 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W0305 21:12:08.741001 621 device_context.cc:465] device: 0, cuDNN Version: 7.6. => pretrained model loaded successfully Epoch: [0][199/1600], lr: 0.00000 Time 1.044 (1.223) Data 0.0003 (0.4569) Loss 1.0267 (1.1224) Epoch: [0][399/1600], lr: 0.01000 Time 1.557 (1.268) Data 1.0433 (0.5760) Loss 1.1810 (1.0765) Epoch: [0][599/1600], lr: 0.00000 Time 1.319 (1.322) Data 0.8051 (0.6646) Loss 0.7047 (0.9411) Epoch: [0][799/1600], lr: 0.01000 Time 1.508 (1.268) Data 0.9931 (0.5015) Loss 0.8654 (0.8181) Epoch: [0][999/1600], lr: 0.00000 Time 1.539 (1.262) Data 1.0248 (0.4835) Loss 0.6578 (0.6222) Epoch: [0][1199/1600], lr: 0.01000 Time 1.397 (1.261) Data 0.8822 (0.4821) Loss 0.4555 (0.5395) Epoch: [0][1399/1600], lr: 0.00000 Time 1.411 (1.256) Data 0.8975 (0.4768) Loss 0.3137 (0.4068) Epoch: [0][1599/1600], lr: 0.01000 Time 1.394 (1.254) Data 0.8796 (0.4755) Loss 0.4796 (0.4184) Test: [199/1000] Time 0.121 (0.142) Pixels Acc 0.839 mIoU 0.500 Test: [399/1000] Time 0.122 (0.140) Pixels Acc 0.835 mIoU 0.499 Test: [599/1000] Time 0.123 (0.140) Pixels Acc 0.841 mIoU 0.507 Test: [799/1000] Time 0.124 (0.140) Pixels Acc 0.843 mIoU 0.512 Test: [999/1000] Time 0.118 (0.140) Pixels Acc 0.839 mIoU 0.513 Testing Results: Pixels Acc 0.839 mIoU 0.513 (0.5128)
训练1轮后,平均交并比为51.3%.
四、效果测试
下面我们来测试下训练了10轮的模型效果。
In [4]!python Lane-Detection-with-ERFNet/test_erfnet_paddle.py --resume Lane-Detection-with-ERFNet/trained/erfnet_best.pdparams
W0305 21:49:27.301187 3291 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W0305 21:49:27.306970 3291 device_context.cc:465] device: 0, cuDNN Version: 7.6. => loading checkpoint 'Lane-Detection-with-ERFNet/trained/erfnet_best.pdparams' => checkpoint loaded successfully Test: [400/3200] Time 0.122 (0.103) Test: [800/3200] Time 0.135 (0.102) Test: [1200/3200] Time 0.085 (0.102) Test: [1600/3200] Time 0.093 (0.102) Test: [2000/3200] Time 0.085 (0.103) Test: [2400/3200] Time 0.130 (0.103) Test: [2800/3200] Time 0.084 (0.104) Test: [3200/3200] Time 0.083 (0.104) finished, #test:3200
可视化输出
模型的输出结果跟数据集的标签都是单通道的图像,因此直接打开的话就是一张黑黑的图像,如果想要看清输出结果,可以将输出结果转换成灰度图:
In [6]%matplotlib inlineimport cv2import numpy as npimport matplotlib.pyplot as plt
index = 10001image = cv2.imread("data/data125507/car_data_2025/JPEGImages/0{}.jpg".format(index))
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
result = cv2.imread("results/result/{}.png".format(index))
result = cv2.cvtColor(result, cv2.COLOR_BGR2GRAY)
plt.imshow(image)
plt.show()
plt.imshow(result)
plt.show()<Figure size 432x288 with 1 Axes>
<Figure size 432x288 with 1 Axes>In [ ]
%cd /home/aistudio/submission/ !python predict.py data.txt result.json
以上就是ERFNet:用于实时语义分割的高效残差分解卷积神经网络的详细内容,更多请关注其它相关文章!
# 多个
# 马村附近网站建设
# 六盘水农产品网站建设
# seo进价推广
# 西丰网站建设
# 山西展示型网站建设
# 抖音理发店怎么做营销推广
# 上饶关键词seo
# 营销推广用移动车辆
# 奶茶行业营销策划推广
# 沽源抖音seo优化
# 采用了
# 提出了
# python
# 是一种
# 还没有
# 的是
# 美图
# 一言
# 所示
# 中文网
# fig
# udio
# red
# ai
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
电动车power灯亮是什么意思
汽车上power是什么意思
solidworks打开igs文件看不见要怎么办解决方法
solidworks打开IGS文件作图教程
8寸照片尺寸多少厘米
品道音响上的power键是什么意思
linux命令行如何使用中文输入法
如何判断固态硬盘端口
照相机上面power是什么意思
access 如何输入命令
cmd如何定时执行命令
光刻机分类有哪些品牌的
旧固态硬盘如何卖出
为什么都用typescript
什么软件能下载夸克视频
1s等于多少ms
单片机怎么加死循环
锤子手机怎么不出5g
vivo手机爱奇艺怎么投屏到电视操作步骤
iphone拍电子屏有横条如何解决
xdm是什么意思
51单片机怎么用flash
如何选择启用固态硬盘
win10如何开启命令行
typescript如何遍历map
如何通过命令行启动tomcat
交管12123协议头不完整是啥意思
如何以管理员身份打开命令提示符
360n6锁屏壁纸怎么设置
市盈率市净率是什么意思
交管12123协议头是什么
油烟机上的power是什么意思
华为交换机 配置 如何复制命令行
为什么夸克无法注销账户
43寸电视长宽多少厘米
电动车power灯亮红灯是什么意思
固态硬盘如何显示
typescript怎么使用vue
春运抢票可以抢几张
复制 命令如何撤销
ai文件在线打开工具有哪些
新网站如何填写域名解析
春运订票什么时候抢票
固态硬盘4k如何看
苹果16有哪些不同
debug中如何用n命令命名程序文件名
学typescript需要什么基础么
如何增加固态硬盘
苹果怎么没出5g手机
如何安装大华固态硬盘
