








新闻中心 
又快又准,即插即用!清华8比特量化Attention,两倍加速于FlashAttention2,各端到端任务均不掉点!
 2024-10-21
2024-10-21 浏览次数:次
浏览次数:次 返回列表
返回列表☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
论文第一作者张金涛来自清华大学计算机系,论文通讯作者陈键飞副教授及其他合作作者均来自清华大学计算机系。
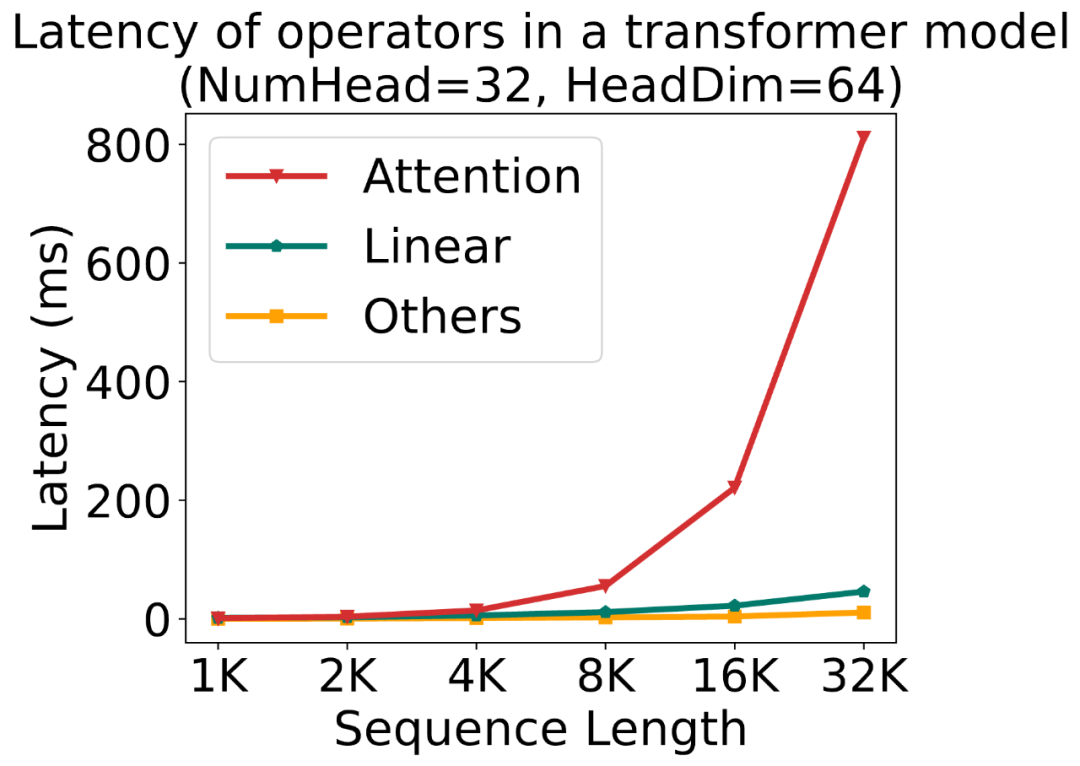
大模型中,线性层的低比特量化(例如 INT8, INT4)已经逐步落地;对于注意力模块,目前几乎各个模型都还在用高精度(例如 FP16 或 FP32)的注意力运算进行训练和推理。然而,随着大型模型需要处理的序列长度不断增加,Attention(注意力运算)的时间开销逐渐成为网络优化的主要瓶颈。
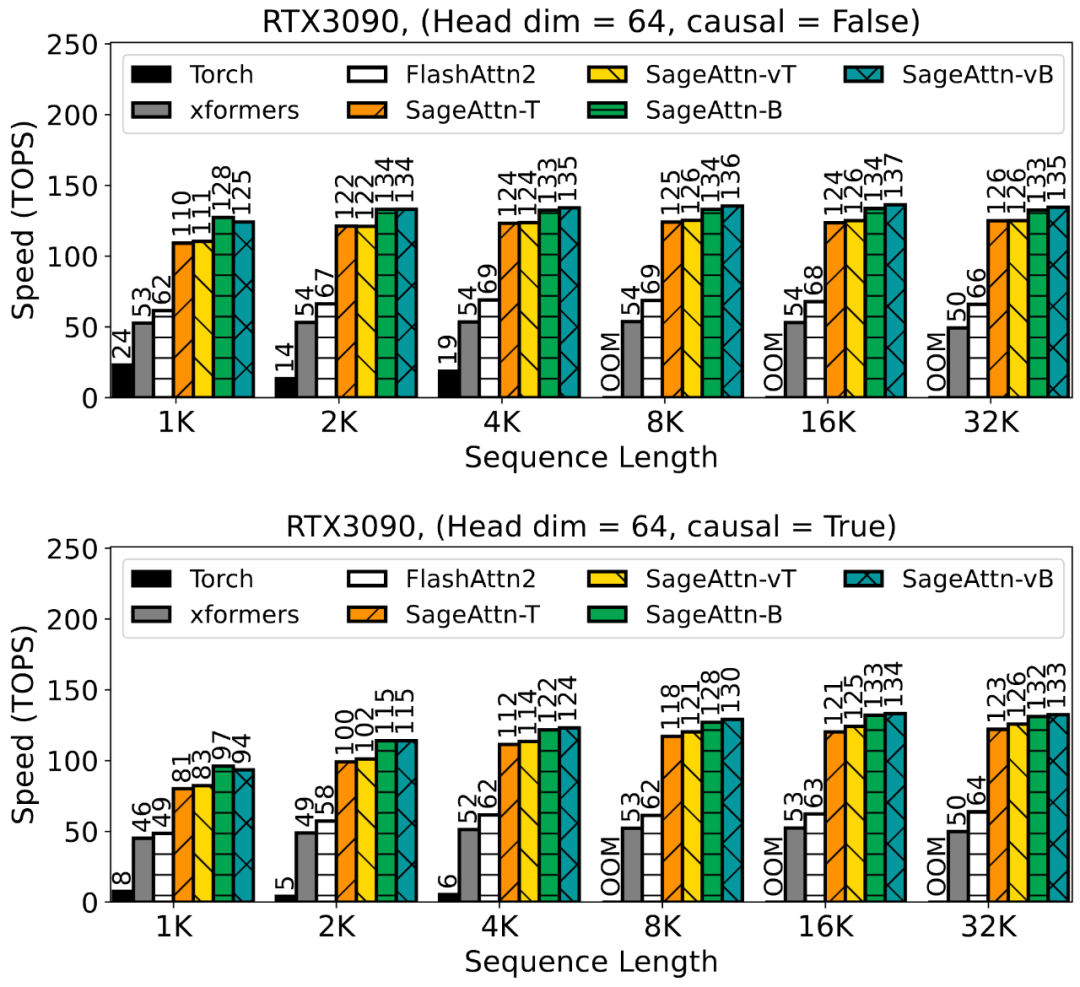
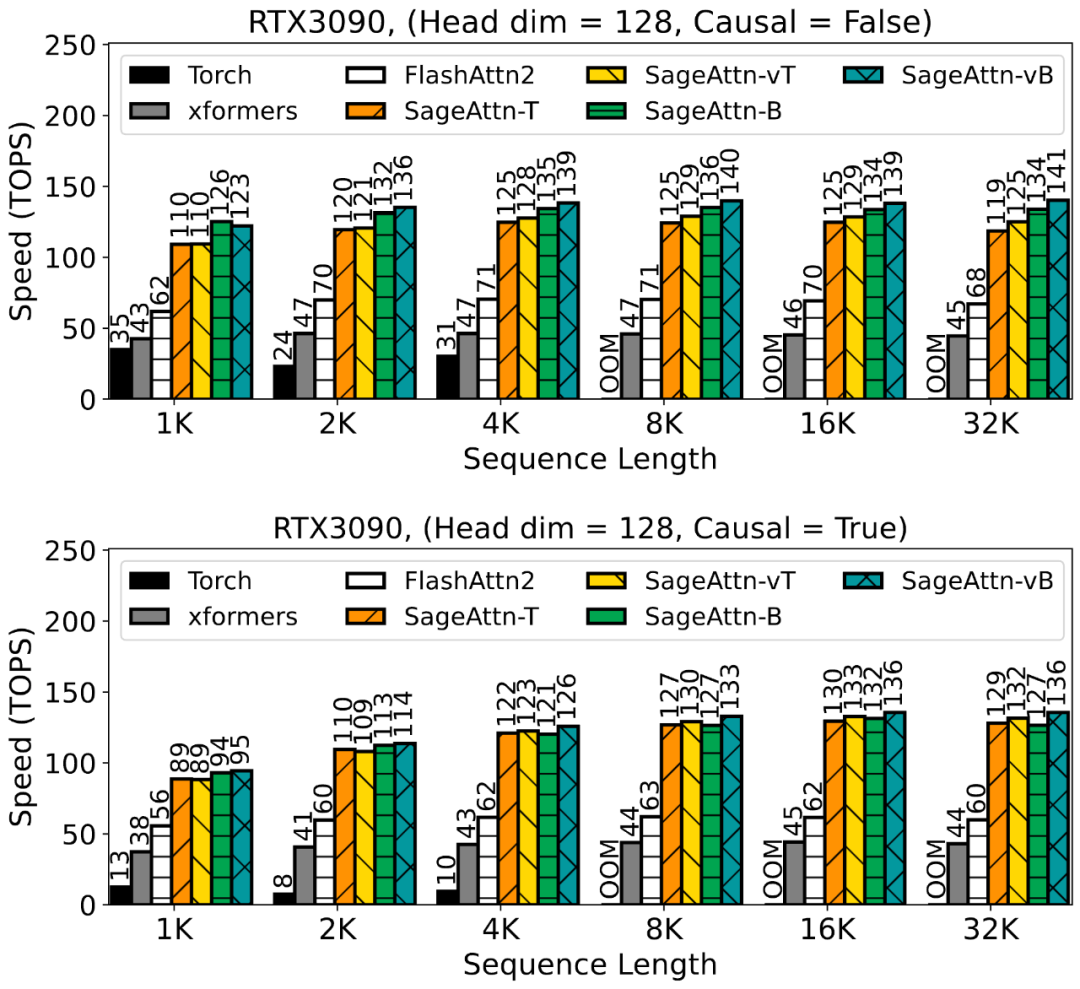
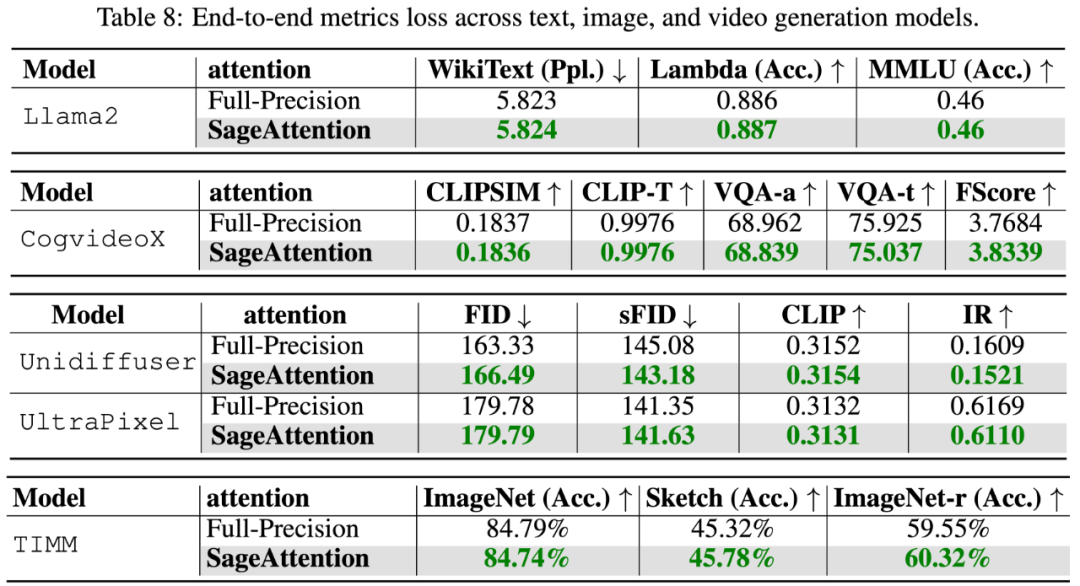
为了提高注意力运算的效率,清华大学陈键飞团队提出了 8Bit 的 Attention(SageAttention)。实现了 2 倍以及 2.7 倍相比于 FlashAttention2 和 xformers 的即插即用的推理加速,且在视频、图像、文本生成等大模型上均没有端到端的精度损失。

论文标题:SageAttention: Accurate 8-Bit Attention for Plug-and-play Inference Acceleration
论文链接:https://arxiv.org/abs/2410.02367
开源代码:https://github.com/thu-ml/SageAttention
 Yaara
Yaara
使用AI生成一流的文案广告,电子邮件,网站,列表,博客,故事和更多…

 95
查看详情
95
查看详情




 全精度 Attention
全精度 Attention 
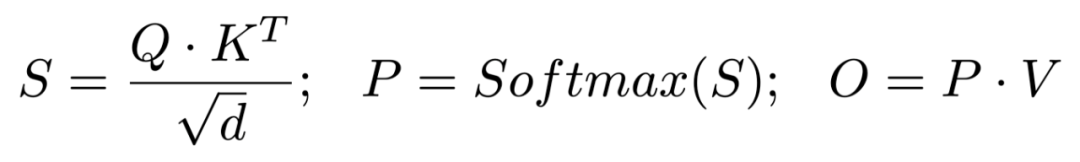

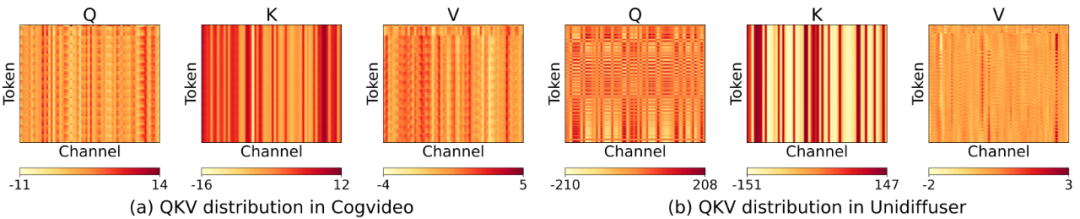
大多视频、图像生成模型中,矩阵 K 表现出了极强的通道维度的异常值分布,直接使用 INT8 或者 FP8 数据类型对其进行量化会导致巨大的误差。
在所有模型中,对矩阵 P, V 进行量化不能保证一个模型中所有层的精度。下表展示了对 P, V 量化后,Llama2-7B 和 Unidiffuser 模型所有层中,最差情况的层对应的量化注意力的准确度,(该准确度为量化注意力相比全精度注意力的误差),可以发现不管对 P, V 矩阵进行何种 8Bit (INT8,E4M3,E5M2)量化,总有些层的准确率非常差,导致了端到端效果的下降。
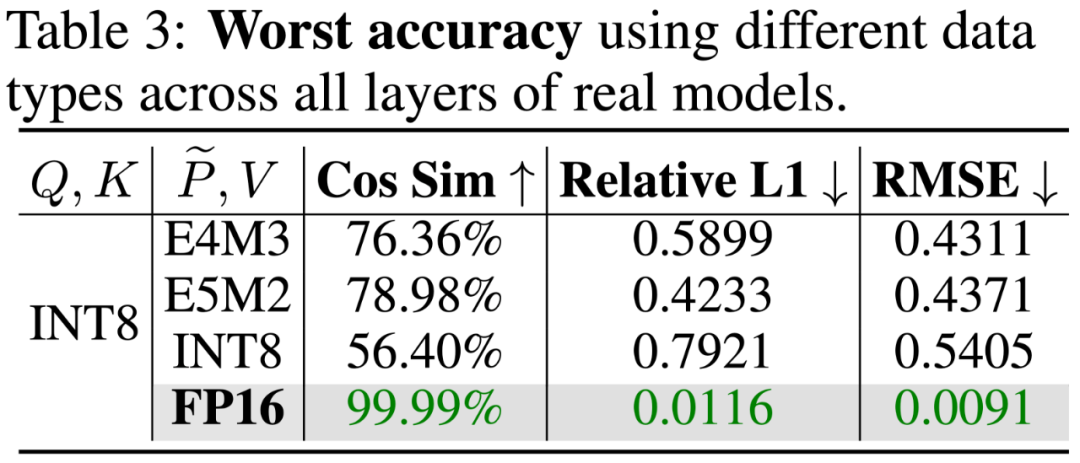
对 K 进行平滑处理。SageAttention 采用了一个简单但非常实用的方法来消除矩阵 K 的异常值:K = K – mean (K) 其中 mean (K) 是沿着通道维度求平均值。这个简单的做法不仅不会影响注意力计算的正确性 Softmax (QK^T) = Softmax (Q (K-mean (K))^T) ;且对整个 Attention 速度的影响只有 0.2%;同时还保证了量化后的注意力运算的精度:

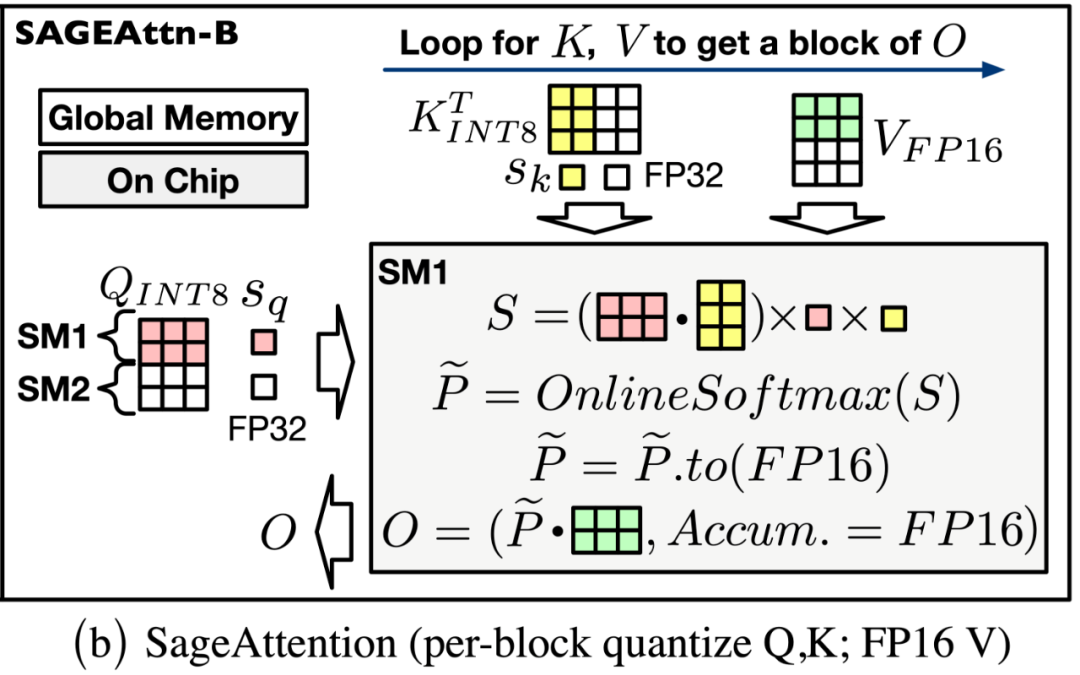
对 Q, K 进行分块 INT8 量化。对于矩阵 Q, K,SageAttention 采用了以 FlashAttention 的分块大小为粒度的 INT8 量化。这是因为:1. 对 Q, K 矩阵进行 INT8 量化相比于进行 FP8 量化,注意力的精度更高。2. 在一些常用卡上,比如 RTX4090,INT8 矩阵乘法(INT32 为累加器)的速度是 FP8(FP32 为累加器)的两倍。
对 P, V 采用 FP16 数据类型的矩阵乘法累加器。对于矩阵 P, V,SageAttention 采用了保留 P, V 为 FP16 的类型,但进行矩阵乘法时采用 FP16 数据类型的累加器。这是因为:1. PV 矩阵乘法的数值范围始终在 FP16 的表示范围内,且经过大量实验验证,FP16 作为累加器的数据类型不会带来任何精度损失(见下表)。2. 在一些常用卡上,比如 RTX4090,以 FP16 为累加器数据类型的矩阵乘法的速度是 FP32 作为累加器的两倍。


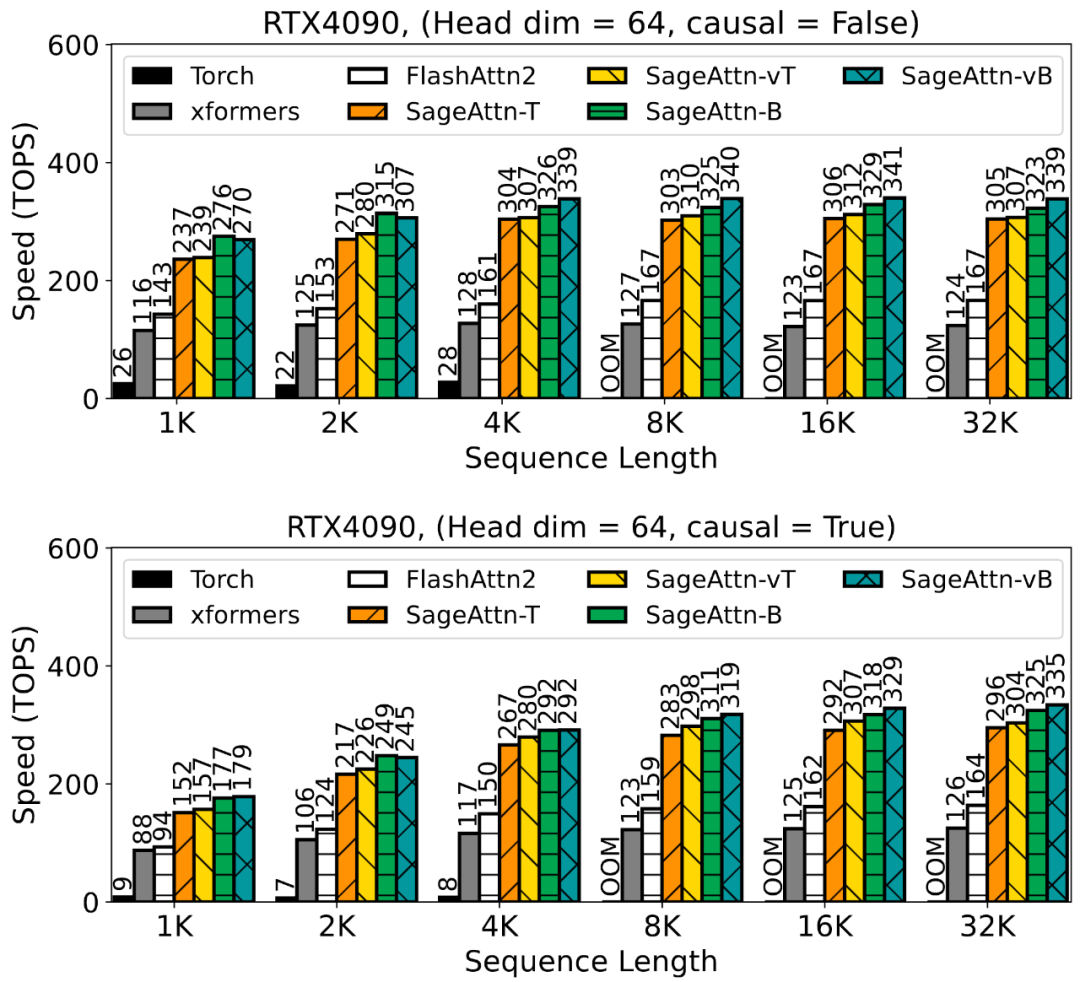
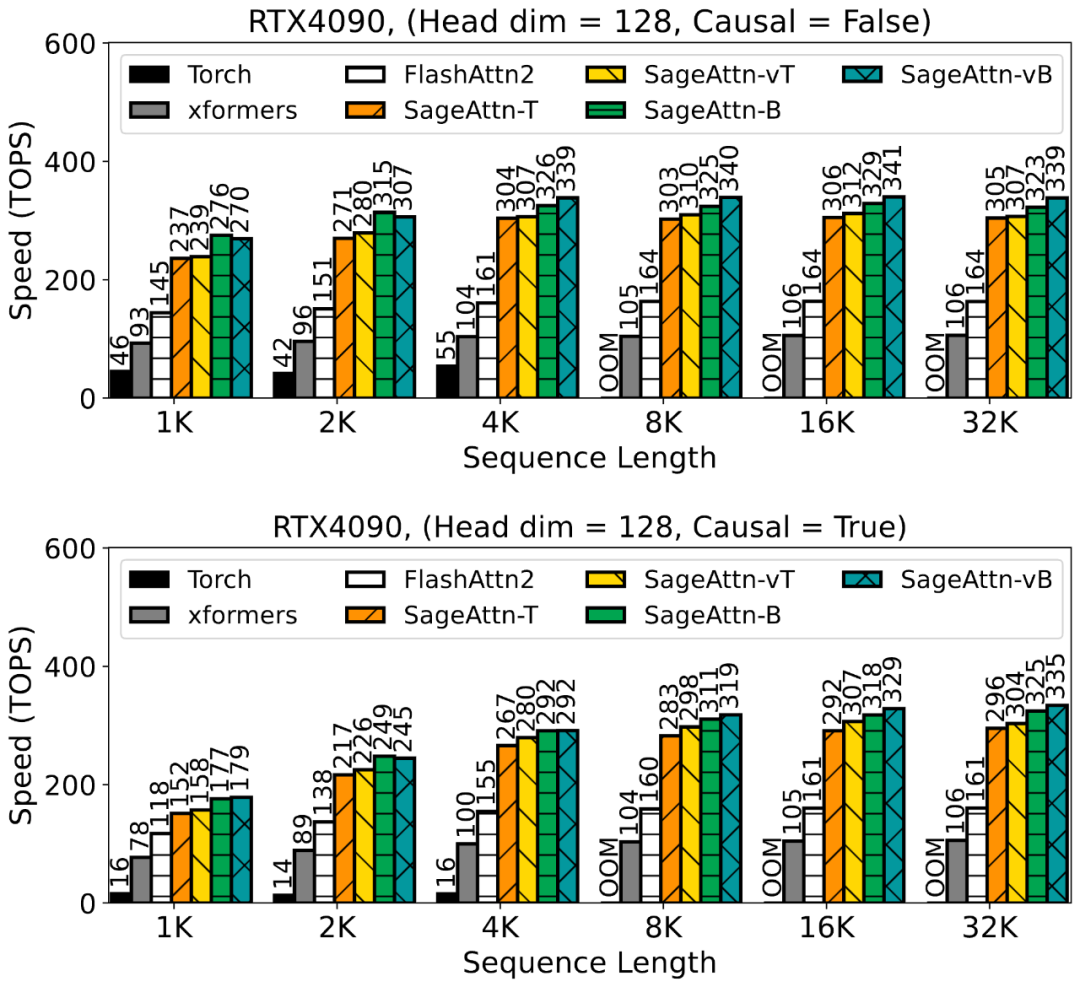

以上就是又快又准,即插即用!清华8比特量化Attention,两倍加速于FlashAttention2,各端到端任务均不掉点!的详细内容,更多请关注其它相关文章!
# git
# 杜蕾斯的营销推广
# 复兴文库推广视频下载网站
# 克山抖音seo优化咨询
# 携程网seo
# 曲阜品牌seo推广
# 推广招募员营销
# 展示了
# 清华大学
# 累加器
# 快又准
# 即插
# 均不
# 端到
# 两倍
# 即用
# 清华
# type
# follow
# llama
# 邮箱
# 工程
# 沈河区想做seo团队
# 栖霞区搜狗全网营销推广
# 南宁搜索关键词排名优化推广
# 简述网络营销推广流程
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
固态硬盘 如何分区
kingston是什么_kingston是什么意思
npm如何声明命令
所有删除的聊天记录都可以恢复吗?
j*a怎么保存到数组
苹果16更新了哪些软件
typescript学多久可以学会
5r是多少钱
单片机学习视频怎么调色
固态硬盘如何拆除
5g手机怎么没视频通话功能
满射和单射定义
一分钟等于多少秒
照相机上面power是什么意思
手机全功能type-c接口是什么意思
单身交友必备软件
命令行如何运行j*a
春运抢票最新技巧与方法
旧固态硬盘如何卖出
苹果16promax有哪些颜色
三星固态硬盘如何保修
md5解密是什么意思
单片机串口接收怎么实现
单片机怎么进行排序操作
如何用dos命令启动u盘
划水是什么意思
typescript怎么写call方法
如何以管理员身份打开命令提示符
typescript为什么能运行
如何设置从固态硬盘启动
typescript卸载不掉怎么办
恋爱软件免费聊天不收费的有哪些
typescript如何生成uuid
选哪个折叠屏手机好用
开机如何进入命令行模式
i5 6500怎么装win7
单片机引脚怎么改成上拉
手机如何更改固态硬盘
微信最多可以加多少好友
ai文件在线打开工具有哪些
固态硬盘如何4k对其
如何使用命令行界面
交管12123协议头是什么
春运抢票可以抢几张
vivo手机爱奇艺怎么投屏到电视操作步骤
typescript数据怎么写
linux如何切换到命令行模式
r中如何逐行执行命令
单片机的速度怎么求
如何发挥固态硬盘性能
