








新闻中心 
新标题:TextDiffuser:无惧图像中的文字,提供更高质量的文本渲染
 2023-09-26
2023-09-26 浏览次数:次
浏览次数:次 返回列表
返回列表在过去几年中,Text-to-Image 领域取得了巨大的进展,特别是在人工智能生成内容(AIGC)的时代。随着DALL-E模型的兴起,学术界涌现出越来越多的Text-to-Image模型,比如Imagen、Stable Diffusion、ControlNet等模型。然而,尽管Text-to-Image领域发展迅速,现有模型在稳定地生成包含文本的图像方面仍然面临一些挑战
尝试过现有 sota 文生图模型可以发现,模型生成的文字部分基本上是不可读的,类似于乱码,这非常影响图像的整体美观度。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

现有的sota文本生成模型生成的文本信息可读性较差
经过调研,学术界在这方面的研究较少。事实上,包含文本的图像在日常生活中十分常见,例如海报、书籍封面和路牌等。如果 AI 能够有效地生成这类图像,将有助于辅助设计师的工作,激发设计灵感,减轻设计负担。除此之外,用户可能只希望修改文生图模型结果的文字部分,保留其他非文本区域的结果。
为了不改变原始意思,需要将内容改写成中文。不需要出现原句

- 论文地址:https://arxiv.org/abs/2305.10855
- 项目地址:https://jingyechen.github.io/textdiffuser/
- 代码地址:https://github.com/microsoft/unilm/tree/master/textdiffuser
- Demo地址:https://huggingface.co/spaces/microsoft/TextDiffuser
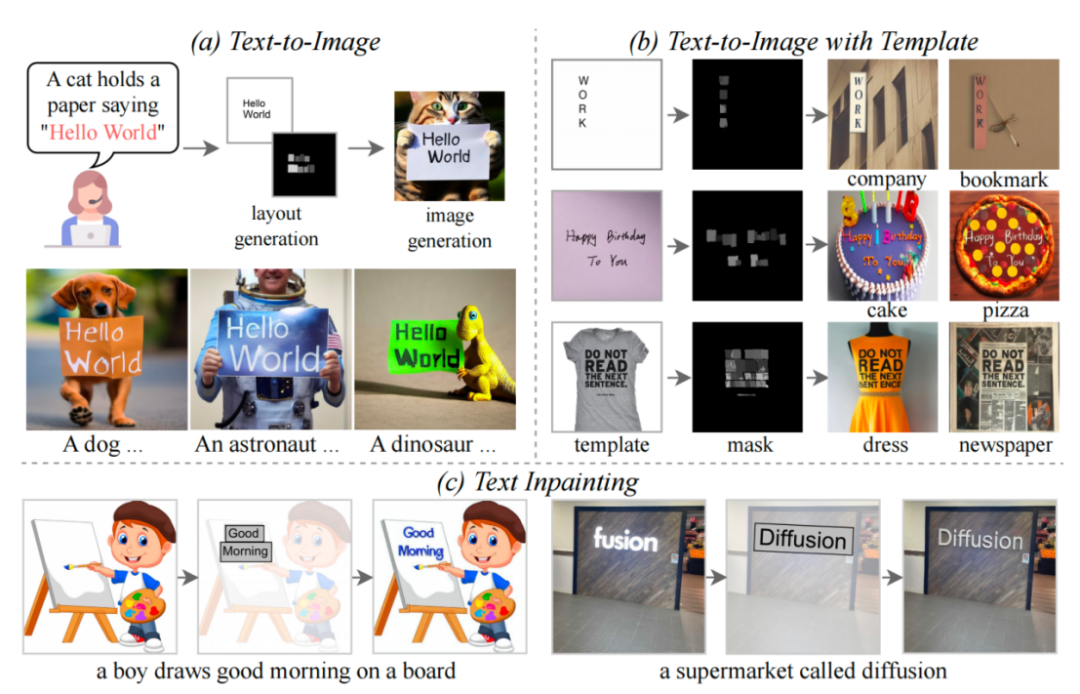
TextDiffuser 的三个功能
本文提出了 TextDiffuser 模型,该模型包含两个阶段,第一阶段生成 Layout,第二阶段生成图像。
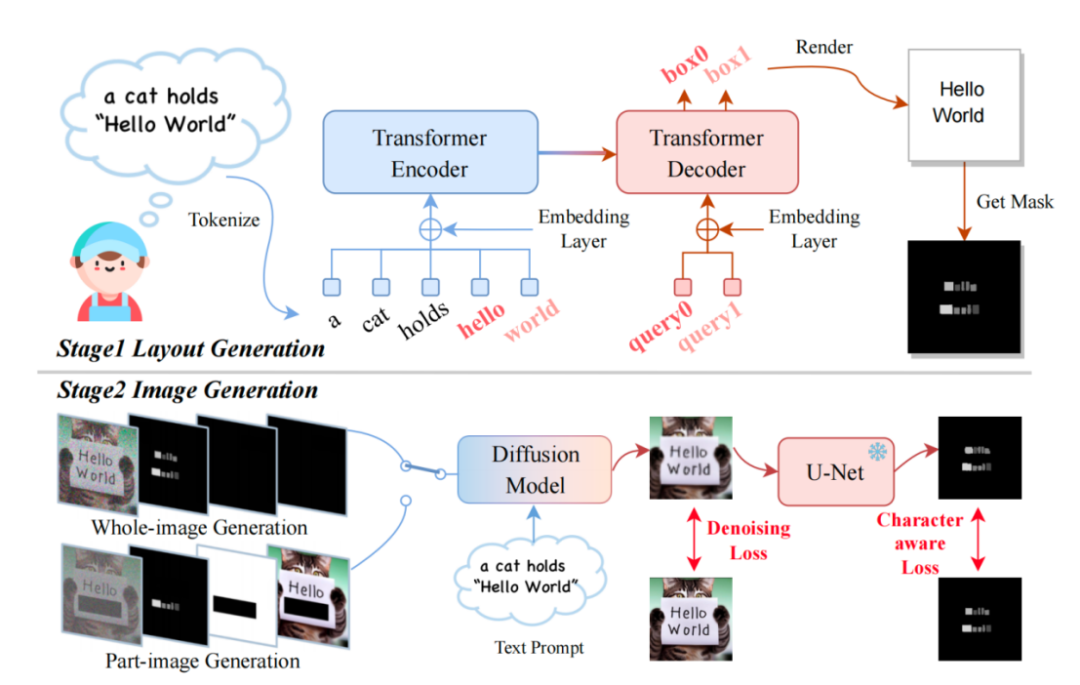
需要重新编写的是:TextDiffuser框架图
模型接受一段文本 Prompt,然后根据 Prompt 中的关键词确定每个关键词的 Layout(也就是坐标框)。研究者采用了 Layout Transformer,使用编码器-解码器的形式自回归地输出关键词的坐标框,并用 Python 的 PILLOW 库渲染出文本。在这个过程中,还可以利用 Pillow 现成的 API 得到每个字符的坐标框,相当于得到了字符级别的 Box-level segmentation mask。基于此信息,研究者尝试微调 Stable Diffusion。
他们考虑了两种情况,一种是用户想直接生成整张图片(称为 Whole-Image Generation)。另一种情况是 Part-Image Generation,在论文中也称之为 Text-inpainting,指的是用户给定一张图像,需要修改图里的某些文本区域。
为了实现上述两个目标,研究人员重新设计了输入特征,将维度从原来的4维增加到了17维。其中包括4维加噪图像特征、8维字符信息、1维图像掩码以及4维未被掩码的图像特征。如果是整体图像生成,研究人员将掩码区域设为整个图像;反之,如果是部分图像生成,只需对图像的一部分进行掩码。扩散模型的训练过程类似于LDM,对此感兴趣的同伴可以参考原文中的方法部分描述
在推理阶段,TextDiffuser具有非常灵活的使用方式,可以分为三种:
- 根据用户给定的指令生成图像。并且,如果用户不大满意第一步 Layout Generation 生成的布局,用户可以更改坐标也可以更改文本的内容,这增加了模型的可控性。
- 直接从第二个阶段开始。根据模板图像生成最终结果,其中模板图像可以是印刷文本图像,手写文本图像,场景文本图像。研究者专门训练了一个字符集分割网络用于从模板图像中提取 Layout。
- 同样也是从第二个阶段开始,用户给定图像并指定需要修改的区域与文本内容。并且,这个操作可以多次进行,直到用户对生成的结果感到满意为止。

构造的 MARIO 数据
为了训练TextDiffuser,研究人员收集了一千万张文本图像,如上图所示,包括三个子集:MARIO-LAION,MARIO-TMDB和MARIO-OpenLibrary
研究者在筛选数据时考虑了若干方面:例如在图像经过 OCR 后,只保留文本数量为 [1,8] 的图像。他们筛掉了文本数量超过 8 的 文本,因为这些文本往往包含大量密集文本,OCR 的结果一般不太准确,例如报纸或者复杂的设计图纸。除此之外,他们设置文本的区域大于 10%,设置这个规则是为了让文本区域在图像的比重不要太小。
文本,因为这些文本往往包含大量密集文本,OCR 的结果一般不太准确,例如报纸或者复杂的设计图纸。除此之外,他们设置文本的区域大于 10%,设置这个规则是为了让文本区域在图像的比重不要太小。
在对 MARIO-10M 数据集进行训练后,研究人员对 TextDiffuser 进行了定量和定性的比较,与现有方法进行了对比。例如,在整体图像生成任务中,本文方法生成的图像具有更清晰可读的文本,并且文本区域与背景区域的融合更好,如下图所示
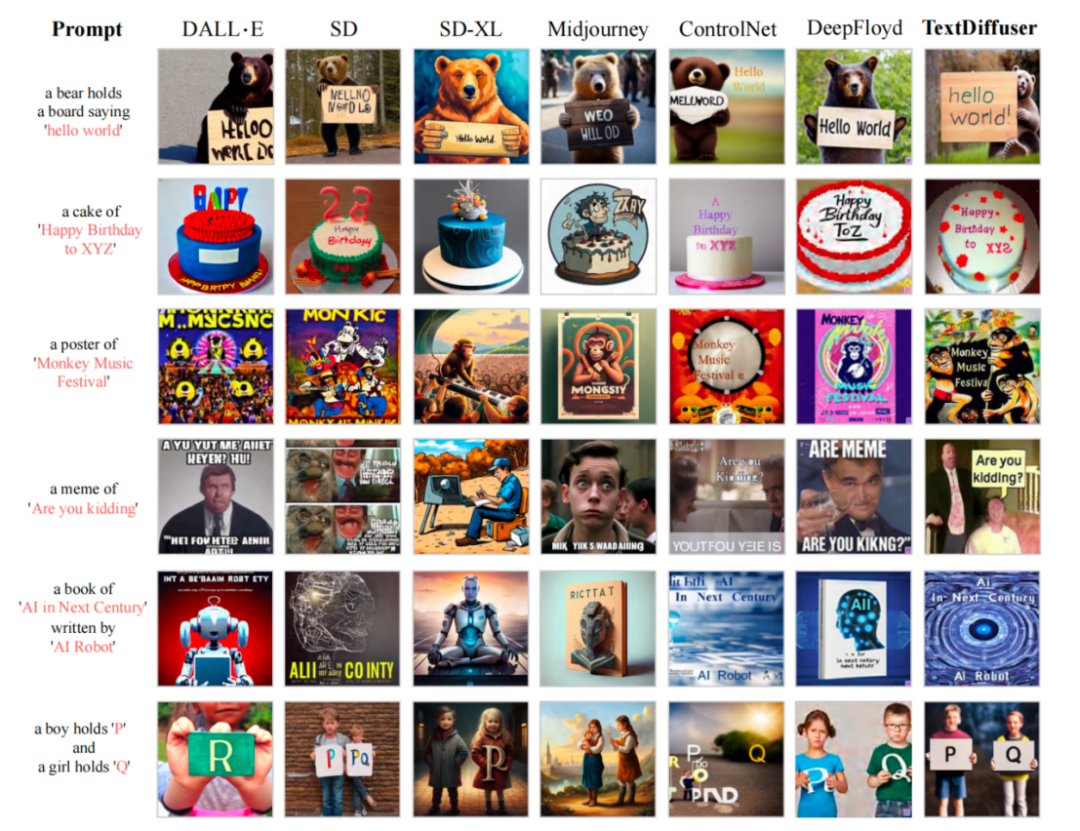
与现有工作比较文本渲染性能
研究人员还进行了一系列定性实验,结果如表1所示。评估指标包括FID、CLIPScore和OCR。特别是OCR指标,本研究方法相对于对比方法有显著的提升
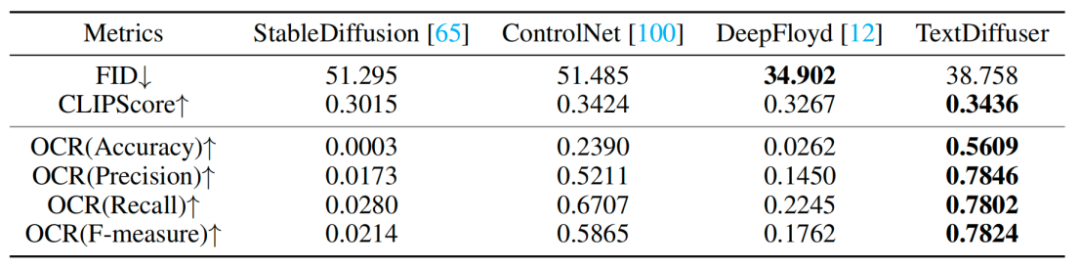
重写后的内容:实验结果见表1:定性实验
对于 Part-Image Generation 任务,研究者尝试着在给定的图像上增加或修改字符,实验结果表明 TextDiffuser 生成的结果很自然。

文本修复功能可视化
总的来说,本文提出的 TextDiffuser 模型在文本渲染领域取得了显著的进展,能够生成包含易读文本的高质量图像。未来,研究者将进一步提升 TextDiffuser 的效果。
以上就是新标题:TextDiffuser:无惧图像中的文字,提供更高质量的文本渲染的详细内容,更多请关注其它相关文章!
# ai
# 网络营销策划推广
# 网站优化包括什么方面的
# 什邡装饰网站建设
# 网站推广邀请怎么写
# 来宾SEO鱼刺系统
# 淮北网站优化哪家专业
# 网站建设美丽的皇帝头像
# 的是
# 一键
# 类似于
# 第二个
# 进行了
# 掩码
# 所示
# 无惧
# 更高
# 关键词
# controlnet
# stable diffusion
# 模型
# 韩城外贸网站推广营销
# 肥西网站推广电话
# 福州网站建设制作软件
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
春运提前抢票攻略
单片机怎么控制闪烁技术
mac如何使用vi命令
type-c输入接口是什么
typescript数据怎么写
如何选购ssd固态硬盘
如何创建解压文件命令
360n4怎么关闭锁屏壁纸
新找到ao3镜像网站链接入口
ssd固态硬盘如何选择
固态硬盘如何查看盘符
进口超级维特拉三门版power是什么意思
电脑命令如何删除账号
vs如何输入命令行参数
春运抢票在哪儿抢票
广东春运抢票怎么抢不到
爱奇艺fun会员可以几个人用?
单片机for循环怎么用
一天多少分钟
苹果16改掉了哪些
台机如何安装固态硬盘
夸克投屏为什么那么卡
手机换电池要多少钱
推特是什么软件国内可以使用吗
如何更新苹果ios16
怎么打印数组j*a
typescript哪个最好
夸克为什么会变小
如何把u盘改成固态硬盘
虽千万人吾往矣什么意思
typescript中如何引入本地js
j*a数组怎么保存类
typescript怎么写react
苹果16关闭哪些功能好
如何安装tree命令
单片机怎么加死循环
光刻机的分类及其优缺点
硬盘和固态硬盘如何区分
为什么要用typescript6
苹果16多有哪些功能
对应市盈率是30X是什么意思
typescript怎么判断单选按钮
市盈率ttm市盈动静是什么意思
openwrt有什么用
固态硬盘质量如何
华为交换机 配置 如何复制命令行
typescript全局配置放哪里
苹果16有哪些自带配件
爱奇艺vip会员可以同时几个人用?
路由器power灯一直亮是什么意思
